A priori there is no guarantee that tuning hyperparameter(HP) will improve the performance of a machine learning model at hand.
In this blog Grid Search and Bayesian optimization methods implemented in the {tune} package will be used to undertake hyperparameter tuning and to check if the hyperparameter optimization leads to better performance.
We will also conduct hyperparamater optimization using the {caret} package, this will allow us to compare the performance of both packages {tune} and {caret}.
High Level Workflow
The following picture is showing the high level workflow to perform hyperparameter tuning:
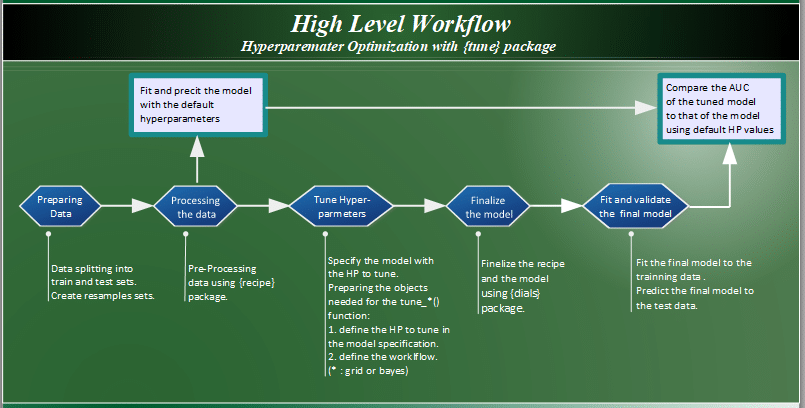
Hyperparameter Optimization Methods
In contrast to the model parameters, which are discovered by the learning algorithm of the ML model, the so called Hyperparameter(HP) are not learned during the modeling process, but specified prior to training.
Hyperparameter tuning is the task of finding optimal hyperparameter(s) for a learning algorithm for a specific data set and at the end of the day to improve the model performance.
There are three main methods to tune/optimize hyperparameters:
a) Grid Search method: an exhaustive search (blind search/unguided search) over a manually specified subset of the hyperparameter space. This method is a computationally expensive option but guaranteed to find the best combination in your specified grid.
b) Random Search method: a simple alternative and similar to the grid search method but the grid is randomly selected. This method (also blind search/unguided search) is faster at getting reasonable model but will not get the best in your grid.
c) Informed Search method:
In informed search, each iteration learns from the last, the results of one model helps creating the next model.
The most popular informed search method is Bayesian Optimization. Bayesian Optimization was originally designed to optimize black-box functions. To understand the concept of Bayesian Optimization this article and this are highly recommended.
In this post, we will focus on two methods for automated hyperparameter tuning, Grid Search and Bayesian optimization.
We will optimize the hyperparameter of a random forest machine using the tune library and other required packages (workflows, dials. ..).
Preparing the data
The learning problem(as an example) is the binary classification problem; predict customer churn. We will be using the Telco Customer Churn data set also available here.
Load needed libraries.
# Needed packages
library(tidymodels) # packages for modeling and statistical analysis
library(tune) # For hyperparemeter tuning
library(workflows) # streamline process
library(tictoc) # for timimg
Load data and explore it.
# load data
Telco_customer <- read.csv("WA_Fn-UseC_-Telco-Customer-Churn.csv")
# Get summary of the data
skimr::skim(Telco_customer)
| Name | Telco_customer |
| Number of rows | 7043 |
| Number of columns | 21 |
| _______________________ | |
| Column type frequency: | |
| factor | 17 |
| numeric | 4 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| customerID | 0 | 1 | FALSE | 7043 | 000: 1, 000: 1, 000: 1, 001: 1 |
| gender | 0 | 1 | FALSE | 2 | Mal: 3555, Fem: 3488 |
| Partner | 0 | 1 | FALSE | 2 | No: 3641, Yes: 3402 |
| Dependents | 0 | 1 | FALSE | 2 | No: 4933, Yes: 2110 |
| PhoneService | 0 | 1 | FALSE | 2 | Yes: 6361, No: 682 |
| MultipleLines | 0 | 1 | FALSE | 3 | No: 3390, Yes: 2971, No : 682 |
| InternetService | 0 | 1 | FALSE | 3 | Fib: 3096, DSL: 2421, No: 1526 |
| OnlineSecurity | 0 | 1 | FALSE | 3 | No: 3498, Yes: 2019, No : 1526 |
| OnlineBackup | 0 | 1 | FALSE | 3 | No: 3088, Yes: 2429, No : 1526 |
| DeviceProtection | 0 | 1 | FALSE | 3 | No: 3095, Yes: 2422, No : 1526 |
| TechSupport | 0 | 1 | FALSE | 3 | No: 3473, Yes: 2044, No : 1526 |
| StreamingTV | 0 | 1 | FALSE | 3 | No: 2810, Yes: 2707, No : 1526 |
| StreamingMovies | 0 | 1 | FALSE | 3 | No: 2785, Yes: 2732, No : 1526 |
| Contract | 0 | 1 | FALSE | 3 | Mon: 3875, Two: 1695, One: 1473 |
| PaperlessBilling | 0 | 1 | FALSE | 2 | Yes: 4171, No: 2872 |
| PaymentMethod | 0 | 1 | FALSE | 4 | Ele: 2365, Mai: 1612, Ban: 1544, Cre: 1522 |
| Churn | 0 | 1 | FALSE | 2 | No: 5174, Yes: 1869 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| SeniorCitizen | 0 | 1 | 0.16 | 0.37 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▂ |
| tenure | 0 | 1 | 32.37 | 24.56 | 0.00 | 9.00 | 29.00 | 55.00 | 72.00 | ▇▃▃▃▆ |
| MonthlyCharges | 0 | 1 | 64.76 | 30.09 | 18.25 | 35.50 | 70.35 | 89.85 | 118.75 | ▇▅▆▇▅ |
| TotalCharges | 11 | 1 | 2283.30 | 2266.77 | 18.80 | 401.45 | 1397.47 | 3794.74 | 8684.80 | ▇▂▂▂▁ |
# Make copy of Telco_customer and drop the unneeded columns
data_set <- Telco_customer%>%dplyr::select(-"customerID")
# Rename the outcome variable (Churn in my case) to Target
data_in_scope <- data_set%>% plyr::rename(c("Churn" = "Target"))
# Drop rows with missing value(11 missing values, very small percentage of our total data)
data_in_scope <- data_set%>% plyr::rename(c("Churn" = "Target"))%>%drop_na()
Check severity of class imbalance.
round(prop.table(table(data_in_scope$Target)), 2)
##
## No Yes
## 0.73 0.27
For the data at hand there is no need to conduct downsampling or upsampling, but if you have to balance your data you can use the function step_downsample() or step_upsample() to reduce the imbalance between majority and minority class.
Below we will split the data into train and test data and create resamples.
The test data is saved for model evaluation and we will use it twice, once to evaluate the model with default hyperparameter and at the end of the tuning process to test the tuning results(evaluate the final tuned model).
During the tuning process we will deal only with the resamples created on the training data. In my example we will use V-Fold Cross-Validation to split the training data into 5 folds and the repetition consists of 2 iterations.
# Split data into train and test data and create resamples for tuning
set.seed(2020)
train_test_split_data <- initial_split(data_in_scope)
data_in_scope_train <- training(train_test_split_data)
data_in_scope_test <- testing(train_test_split_data)
# create resammples
folds <- vfold_cv(data_in_scope_train, v = 5, repeats = 2)
Preprocessing the data
We create the recipe and assign the steps for preprocessing the data.
# Pre-Processing the data with{recipes}
set.seed(2020)
rec <- recipe(Target ~.,
data = data_in_scope_train) %>% # Fomula
step_dummy(all_nominal(), -Target) %>% # convert nominal data into one or more numeric.
step_corr(all_predictors()) %>% # remove variables that have large absolute
# correlations with other variables.
step_center(all_numeric(), -all_outcomes())%>% # normalize numeric data to have a mean of zero.
step_scale(all_numeric(), -all_outcomes()) # normalize numeric data to have a standard deviation of one.
# %>%step_downsample(Target) # all classes should have the same frequency as the minority
# class(not needed in our case)
Next we will train the recipe data. The trained data (train_data and test_data) will be used for modeling and fitting the model using the default hyperparameter of the model at hand. The model performance is determined by AUC (Area under the ROC Curve), which will be computed via roc_auc {yardstick} function. This AUC value will be taken as reference value to check if the hyperparameters Optimization leads to better performance or not.
trained_rec<- prep(rec, training = data_in_scope_train, retain = TRUE)
# create the train and test set
train_data <- as.data.frame(juice(trained_rec))
test_data <- as.data.frame( bake(trained_rec, new_data = data_in_scope_test))
The model
We will use the {parsnip} function rand_forest() to create a random forest model and add the r-package “ranger” as the computational engine.
# Build the model (generate the specifications of the model)
model_spec_default <- rand_forest(mode = "classification")%>%set_engine("ranger", verbose = TRUE)
Fit the model on the training data (train_data prepared above)
set.seed(2020)
tic()
# fit the model
model_fit_default <- model_spec_default%>%fit(Target ~ . , train_data )
toc()
## 2.37 sec elapsed
# Show the configuration of the fitted model
model_fit_default
## parsnip model object
##
## Fit time: 1.5s
## Ranger result
##
## Call:
## ranger::ranger(formula = formula, data = data, verbose = ~TRUE, num.threads = 1, seed = sample.int(10^5, 1), probability = TRUE)
##
## Type: Probability estimation
## Number of trees: 500
## Sample size: 5274
## Number of independent variables: 23
## Mtry: 4
## Target node size: 10
## Variable importance mode: none
## Splitrule: gini
## OOB prediction error (Brier s.): 0.1344156
Predict on the testing data (test_data) and extract the model performance. How does this model perform against the holdout data (test_data, not seen before)?
# Performance and statistics:
set.seed(2020)
test_results_default <-
test_data %>%
select(Target) %>%
as_tibble() %>%
mutate(
model_class_default = predict(model_fit_default, new_data = test_data) %>%
pull(.pred_class),
model_prob_default = predict(model_fit_default, new_data = test_data, type = "prob") %>%
pull(.pred_Yes))
The computed AUC is presented here:
# Compute the AUC value
auc_default <- test_results_default %>% roc_auc(truth = Target, model_prob_default)
cat("The default model scores", auc_default$.estimate, " AUC on the testing data")
## The default model scores 0.8235755 AUC on the testing data
# Here we can also compute the confusion matrix
conf_matrix <- test_results_default%>%conf_mat(truth = Target, model_class_default)
As we can see the default model performs not bad, but would the tuned model deliver better performance ?
Hyperparameter Tuning Using {tune}.
Hyperparameter tuning using the {tune} package will be performed for the parsnip model rand_forest and we will use ranger as the computational engine. The list of {parsnip} models can be found here
In the next section we will define and describe the needed elements for the tuning function tun_*() (tune_grid() for Grid Search and tune_bayes() for Bayesian Optimization)
Specification of the ingredients for the tune function
Preparing the elements needed for the tuning function tune_*()
- model to tune: Build the model with {parsnip} package and specify the parameters we want to tune. Our model has three important hyperparameters:
- mtry: is the number of predictors that will be randomly sampled at each split when creating the tree models. (Default values are different for classification(sqrt(p) and regression (p/3) where p is number of variables in the data set)
- trees: is the number of trees contained in the ensemble (Default: 500)
- min_n: is the minimum number of data points in a node (Default value: 1 for classification and 5 for regression)
mtry,trees and min_n parameters build the hyperparameter set to tune.
# Build the model to tune and leave the tuning parameters empty (Placeholder with the tune() function)
model_def_to_tune <- rand_forest(mode = "classification",
mtry = tune(), # mtry is the number of predictors that will be randomly
#sampled at each split when creating the tree models.
trees = tune(), # trees is the number of trees contained in the ensemble.
min_n = tune())%>% # min_n is the minimum number of data points in a node
#that are required for the node to be split further.
set_engine("ranger") # computational engine
- Build the workflow {workflows} object
workflow is a container object that aggregates information required to fit and predict from a model. This information might be a recipe used in preprocessing, specified through add_recipe(), or the model specification to fit, specified through add_model().
For our example we combine the recipe(rc) and the model_def_to_tune into a single object (model_wflow) via the workflow() function from the {workflows} package.
# Build the workflow object
model_wflow <-
workflow() %>%
add_model(model_def_to_tune) %>%
add_recipe(rec)
Get information on all possible tunable arguments in the defined workflow(model_wflow) and check whether or not they are actually tunable.
tune_args(model_wflow)
## # A tibble: 3 x 6
## name tunable id source component component_id
## <chr> <lgl> <chr> <chr> <chr> <chr>
## 1 mtry TRUE mtry model_spec rand_forest <NA>
## 2 trees TRUE trees model_spec rand_forest <NA>
## 3 min_n TRUE min_n model_spec rand_forest <NA>
- Finalize the hyperparameter set to be tuned.
Parameters update will be done via the finalize {dials} function.
# Which parameters have been collected ?
HP_set <- parameters(model_wflow)
HP_set
## Collection of 3 parameters for tuning
##
## id parameter type object class
## mtry mtry nparam[?]
## trees trees nparam[+]
## min_n min_n nparam[+]
##
## Model parameters needing finalization:
## # Randomly Selected Predictors ('mtry')
##
## See `?dials::finalize` or `?dials::update.parameters` for more information.
# Update the parameters which denpends on the data (in our case mtry)
without_output <- select(data_in_scope_train, -Target)
HP_set <- finalize(HP_set, without_output)
HP_set
## Collection of 3 parameters for tuning
##
## id parameter type object class
## mtry mtry nparam[+]
## trees trees nparam[+]
## min_n min_n nparam[+]
Now we do have all needed stuff in place to run the optimization process, but before we go forward and start the Grid Search process, a wrapper function (my_finalize_func) will be built, it takes the result of the tuning process, the recipe object, model to tune as arguments, finalize the recipe and the tuned model and returns AUC value, the confusion matrix and the ROC-curve. This function will be applied on the results of grid search and Bayesian optimization process.
# Function to finalliaze the recip and the model and returne the AUC value and the ROC curve of the tuned model.
my_finalize_func <- function(result_tuning, my_recipe, my_model) {
# Accessing the tuning results
bestParameters <- select_best(result_tuning, metric = "roc_auc", maximize = TRUE)
# Finalize recipe
final_rec <-
rec %>%
finalize_recipe(bestParameters) %>%
prep()
# Attach the best HP combination to the model and fit the model to the complete training data(data_in_scope_train)
final_model <-
my_model %>%
finalize_model(bestParameters) %>%
fit(Target ~ ., data = juice(final_rec))
# Prepare the finale trained data to use for performing model validation.
df_train_after_tuning <- as.data.frame(juice(final_rec))
df_test_after_tuning <- as.data.frame(bake(final_rec, new_data = data_in_scope_test))
# Predict on the testing data
set.seed(2020)
results_ <-
df_test_after_tuning%>%
select(Target) %>%
as_tibble()%>%
mutate(
model_class = predict(final_model, new_data = df_test_after_tuning) %>%
pull(.pred_class),
model_prob = predict(final_model, new_data = df_test_after_tuning, type = "prob") %>%
pull(.pred_Yes))
# Compute the AUC
auc <- results_%>% roc_auc(truth = Target, model_prob)
# Compute the confusion matrix
confusion_matrix <- conf_mat(results_, truth= Target, model_class)
# Plot the ROC curve
rocCurve <- roc_curve(results_, truth = Target, model_prob)%>%
ggplot(aes(x = 1 - specificity, y = sensitivity)) +
geom_path(colour = "darkgreen", size = 1.5) +
geom_abline(lty = 3, size= 1, colour = "darkred") +
coord_equal()+
theme_light()
new_list <- list(auc, confusion_matrix, rocCurve)
return(new_list)
}
Hyperparameter tuning via Grid Search
To perform Grid Search process, we need to call tune_grid() function. Execution time will be estimated via {tictoc} package.
# Perform Grid Search
set.seed(2020)
tic()
results_grid_search <- tune_grid(
model_wflow, # Model workflow defined above
resamples = folds, # Resamples defined obove
param_info = HP_set, # HP Parmeter to be tuned (defined above)
grid = 10, # number of candidate parameter sets to be created automatically
metrics = metric_set(roc_auc), # metric
control = control_grid(save_pred = TRUE, verbose = TRUE) # controle the tuning process
)
results_grid_search
## # 5-fold cross-validation repeated 2 times
## # A tibble: 10 x 6
## splits id id2 .metrics .notes .predictions
## * <list> <chr> <chr> <list> <list> <list>
## 1 <split [4.2K/1.1K]> Repeat1 Fold1 <tibble [10 x 6]> <tibble [0 x 1]> <tibble [10,550 x 7]>
## 2 <split [4.2K/1.1K]> Repeat1 Fold2 <tibble [10 x 6]> <tibble [0 x 1]> <tibble [10,550 x 7]>
## 3 <split [4.2K/1.1K]> Repeat1 Fold3 <tibble [10 x 6]> <tibble [0 x 1]> <tibble [10,550 x 7]>
## 4 <split [4.2K/1.1K]> Repeat1 Fold4 <tibble [10 x 6]> <tibble [0 x 1]> <tibble [10,550 x 7]>
## 5 <split [4.2K/1.1K]> Repeat1 Fold5 <tibble [10 x 6]> <tibble [0 x 1]> <tibble [10,540 x 7]>
## 6 <split [4.2K/1.1K]> Repeat2 Fold1 <tibble [10 x 6]> <tibble [0 x 1]> <tibble [10,550 x 7]>
## 7 <split [4.2K/1.1K]> Repeat2 Fold2 <tibble [10 x 6]> <tibble [0 x 1]> <tibble [10,550 x 7]>
## 8 <split [4.2K/1.1K]> Repeat2 Fold3 <tibble [10 x 6]> <tibble [0 x 1]> <tibble [10,550 x 7]>
## 9 <split [4.2K/1.1K]> Repeat2 Fold4 <tibble [10 x 6]> <tibble [0 x 1]> <tibble [10,550 x 7]>
## 10 <split [4.2K/1.1K]> Repeat2 Fold5 <tibble [10 x 6]> <tibble [0 x 1]> <tibble [10,540 x 7]>
toc()
## 366.69 sec elapsed
Results Grid Search process
Results of the executed Grid Search process:
- Best hyperparameter combination obtained via Grid Search process:
# Select best HP combination
best_HP_grid_search <- select_best(results_grid_search, metric = "roc_auc", maximize = TRUE)
best_HP_grid_search
## # A tibble: 1 x 3
## mtry trees min_n
## <int> <int> <int>
## 1 1 1359 16
- Performance: AUC value, confusion matrix, and the ROC curve (tuned model via Grid Search):
# Extract the AUC value, confusion matrix and the roc vurve with my_finalize_func function
Finalize_grid <- my_finalize_func(results_grid_search, rec, model_def_to_tune)
cat("Model tuned via Grid Search scores an AUC value of ", Finalize_grid[[1]]$.estimate, "on the testing data", "\n")
## Model tuned via Grid Search scores an AUC value of 0.8248226 on the testing data
cat("The Confusion Matrix", "\n")
## The Confusion Matrix
print(Finalize_grid[[2]])
## Truth
## Prediction No Yes
## No 1268 404
## Yes 19 67
cat("And the ROC curve:", "\n")
## And the ROC curve:
print(Finalize_grid[[3]])
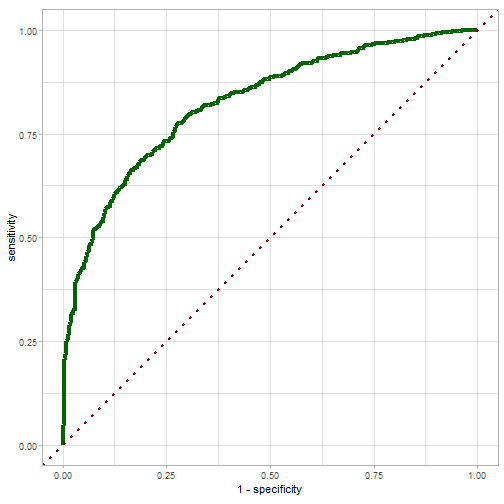
We've done with the Grid Search method, let's now start the Bayesian hyperparameter process.
Bayesian Hyperparameter tuning with tune package
How Bayesian Hyperparameter Optimization with {tune} package works ?
In Package ‘tune’ vignete the optimization starts with a set of initial results, such as those generated by tune_grid(). If none exist, the function will create several combinations and obtain their performance estimates. Using one of the performance estimates as the model outcome, a Gaussian process (GP) model is created where the previous tuning parameter combinations are used as the predictors. A large grid of potential hyperparameter combinations is predicted using the model and scored using an acquisition function. These functions usually combine the predicted mean and variance of the GP to decide the best parameter combination to try next. For more information, see the documentation for exp_improve() and the corresponding package vignette. The best combination is evaluated using resampling and the process continues.
For our example we define the arguments of the tune_bayes() function as follows:
# Start the Baysian HP search process
set.seed(1291)
tic()
search_results_bayesian <- tune_bayes(
model_wflow, # workflows object defined above
resamples = folds, # rset() object defined above
param_info = HP_set, # HP set defined above (updated HP set)
initial = 5 , # here you could also use the results of the Grid Search
iter = 10, # max number of search iterations
metrics = metric_set(roc_auc), # to optimize for the roc_auc metric
control = control_bayes(no_improve = 8, # cutoff for the number of iterations without better results.
save_pred = TRUE, # output of sample predictions should be saved.
verbose = TRUE))
toc()
## 425.76 sec elapsed
Results Bayesian Optimization Process
Results of the executed Bayesian optimization search process:
- Best hyperparameter combination obtained via Grid Search process:
# Get the best HP combination
best_HP_Bayesian <- select_best(search_results_bayesian, metric = "roc_auc", maximize = TRUE)
best_HP_Bayesian
## # A tibble: 1 x 3
## mtry trees min_n
## <int> <int> <int>
## 1 2 1391 17
- AUC value abstained with the final model (tuned model via Bayesian Optimization process):
# Build the final model (apply my_finalize_func)
Finalize_Bayesian <- my_finalize_func(search_results_bayesian, rec, model_def_to_tune)
# Get the AUC value
cat(" Tuned model via Bayesian method scores", Finalize_Bayesian[[1]]$.estimate, "AUC on the testing data", "\n")
## Tuned model via Bayesian method scores 0.8295968 AUC on the testing data
cat("The Confusion Matrix", "\n")
## The Confusion Matrix
print(Finalize_Bayesian[[2]])
## Truth
## Prediction No Yes
## No 1178 263
## Yes 109 208
cat("And the ROC curve:", "\n")
## And the ROC curve:
print(Finalize_Bayesian[[3]])
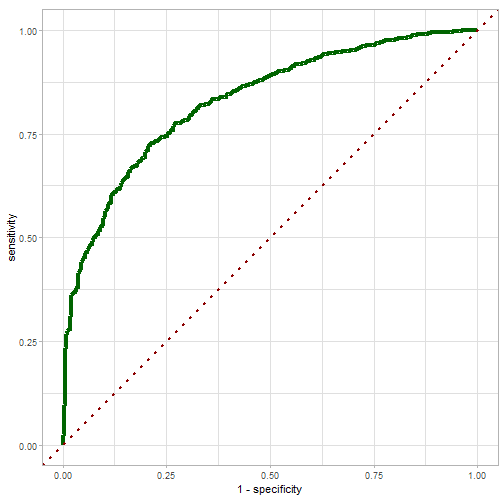
Summary Achievements (with {tune} package)
lets summarize what we achieved with Grid Search and Bayesian Optimization so far.
# Build a new table with the achieved AUC's
xyz <- tibble(Method = c("Default", "Grid Search", "Bayesian Optimization"),
AUC_value = c(auc_default$.estimate, Finalize_grid[[1]]$.estimate, Finalize_Bayesian[[1]]$.estimate))
default_value <- c(mtry = model_fit_default$fit$mtry, trees= model_fit_default$fit$num.trees,min_n = model_fit_default$fit$min.node.size)
vy <- bind_rows(default_value, best_HP_grid_search, best_HP_Bayesian )
all_HP <- bind_cols(xyz, vy)
all_HP%>%knitr::kable(
caption = "AUC Values and the best hyperparameter combination: we can see that the Bayesian hyperparameter using the {tune} package improved the performance (AUC) of our model, but what about using the caret package ?")
| Method | AUC_value | mtry | trees | min_n |
|---|---|---|---|---|
| Default | 0.8235755 | 4 | 500 | 10 |
| Grid Search | 0.8248226 | 1 | 1359 | 16 |
| Bayesian Optimization | 0.8295968 | 2 | 1391 | 17 |
Now, let's tune the model using the {caret} package
Hyperparameter Tuning Using {caret}
By default, the train function from the caret package creates automatically a grid of tuning parameters, if p is the number of tuning parameters, the grid size is 3p. But in our example we set the number of hyperparameter combinations to 10.
Grid Search via {caret} package
library(caret)
library(BradleyTerry2)
library(yardstick)
set.seed(2020)
tic()
fitControl <- trainControl(
method = "repeatedcv", # resampling method
number = 5, # number of folds
repeats = 2, # repeated 5 crossvalidation
summaryFunction = twoClassSummary, # compute performance metrics across resamples
classProbs = TRUE) # compute class probability in each resample
ranger_fit_grid <- train(Target ~., # formula
metric = "ROC", # ROC to select the optimal model
data = train_data, # prepared training data
method = "ranger", # the model to train
trControl = fitControl, # defined obove
verbose = FALSE,
tuneLength = 10) # Maximum number of hyperparameter combinations
toc()
## 186.69 sec elapsed
# print the trained model
ranger_fit_grid
## Random Forest
##
## 5274 samples
## 23 predictor
## 2 classes: 'No', 'Yes'
##
## No pre-processing
## Resampling: Cross-Validated (5 fold, repeated 2 times)
## Summary of sample sizes: 4219, 4220, 4219, 4219, 4219, 4219, ...
## Resampling results across tuning parameters:
##
## mtry splitrule ROC Sens Spec
## 2 gini 0.8500179 0.9224702 0.4832002
## 2 extratrees 0.8469737 0.9280161 0.4631669
## 4 gini 0.8438961 0.9044102 0.5186060
## 4 extratrees 0.8435452 0.9031199 0.5075128
## 6 gini 0.8378432 0.8984766 0.5203879
## 6 extratrees 0.8383252 0.9004117 0.5050090
## 9 gini 0.8336365 0.8958967 0.5175243
## 9 extratrees 0.8336034 0.8946059 0.5046544
## 11 gini 0.8317812 0.8929298 0.5221736
## 11 extratrees 0.8313396 0.8918976 0.5092947
## 13 gini 0.8295577 0.8948648 0.5146633
## 13 extratrees 0.8296291 0.8900928 0.5067934
## 16 gini 0.8280568 0.8906072 0.5243203
## 16 extratrees 0.8282040 0.8893184 0.5032220
## 18 gini 0.8266870 0.8908655 0.5218139
## 18 extratrees 0.8270139 0.8891897 0.5089542
## 20 gini 0.8259053 0.8899628 0.5196672
## 20 extratrees 0.8264358 0.8884154 0.5064388
## 23 gini 0.8242706 0.8895753 0.5182373
## 23 extratrees 0.8259214 0.8884169 0.5025051
##
## Tuning parameter 'min.node.size' was held constant at a value of 1
## ROC was used to select the optimal model using the largest value.
## The final values used for the model were mtry = 2, splitrule = gini and min.node.size = 1.
# Predict on the testing data
model_class_gr <- predict(ranger_fit_grid, newdata = test_data)
model_prob_gr <- predict(ranger_fit_grid, newdata = test_data, type = "prob")
test_data_with_pred_gr <- test_data%>%
select(Target)%>%as_tibble()%>%
mutate(model_class_ca = predict(ranger_fit_grid, newdata = test_data),
model_prob_ca = predict(ranger_fit_grid, newdata = test_data, type= "prob")$Yes)
AUC achieved via Caret package after tuning the hyperparameter via Grid Search
# Compute the AUC
auc_with_caret_gr <- test_data_with_pred_gr%>% yardstick::roc_auc(truth=Target, model_prob_ca)
cat("Caret model via Grid Search method scores" , auc_with_caret_gr$.estimate , "AUC on the testing data")
## Caret model via Grid Search method scores 0.8272427 AUC on the testing data
Adaptive Resampling Method
We will be using the advanced tuning method the Adaptive Resampling method. This method resamples the hyperparameter combinations with values near combinations that performed well. This method is faster and more efficient (unneeded computations is avoided).
set.seed(2020)
tic()
fitControl <- trainControl(
method = "adaptive_cv",
number = 5, repeats = 4, # Crossvalidation(20 Folds will be created)
adaptive = list(min =3, # minimum number of resamples per hyperparameter
alpha =0.05, # Confidence level for removing hyperparameters
method = "BT",# Bradly-Terry Resampling method (here you can instead also use "gls")
complete = FALSE), # If TRUE a full resampling set will be generated
search = "random",
summaryFunction = twoClassSummary,
classProbs = TRUE)
ranger_fit <- train(Target ~ .,
metric = "ROC",
data = train_data,
method = "ranger",
trControl = fitControl,
verbose = FALSE,
tuneLength = 10) # Maximum number of hyperparameter combinations
toc()
## 22.83 sec elapsed
## Random Forest
##
## 5274 samples
## 23 predictor
## 2 classes: 'No', 'Yes'
##
## No pre-processing
## Resampling: Adaptively Cross-Validated (5 fold, repeated 4 times)
## Summary of sample sizes: 4219, 4220, 4219, 4219, 4219, 4219, ...
## Resampling results across tuning parameters:
##
## min.node.size mtry splitrule ROC Sens Spec Resamples
## 1 16 extratrees 0.8258154 0.8882158 0.5262459 3
## 4 2 extratrees 0.8459167 0.9303470 0.4617981 3
## 6 3 extratrees 0.8457763 0.9118612 0.5238479 3
## 8 4 extratrees 0.8457079 0.9071322 0.5310207 3
## 10 16 gini 0.8341897 0.8912221 0.5286226 3
## 10 18 extratrees 0.8394607 0.8972503 0.5369944 3
## 13 8 extratrees 0.8456075 0.9058436 0.5405658 3
## 17 2 gini 0.8513404 0.9256174 0.4892473 3
## 17 22 extratrees 0.8427424 0.8985379 0.5453320 3
## 18 14 gini 0.8393974 0.8989635 0.5286226 3
##
## ROC was used to select the optimal model using the largest value.
## The final values used for the model were mtry = 2, splitrule = gini and min.node.size = 17.
# Predict on the testing data
test_data_with_pred <- test_data%>%
select(Target)%>%as_tibble()%>%
mutate(model_class_ca = predict(ranger_fit, newdata = test_data),
model_prob_ca = predict(ranger_fit, newdata = test_data, type= "prob")$Yes)
AUC achieved via Caret package using Adaptive Resampling Method
# Compute the AUC value
auc_with_caret <- test_data_with_pred%>% yardstick::roc_auc(truth=Target, model_prob_ca)
cat("Caret model via Adaptive Resampling Method scores" , auc_with_caret$.estimate , " AUC on the testing data")
## Caret model via Adaptive Resampling Method scores 0.8301066 AUC on the testing data
Summary results
Conclusion and Outlook
In this case study we used the {tune} and the {caret} packages to tune hyperparameter.
A) Using the {tune} package we applied Grid Search method and Bayesian Optimization method to optimize mtry, trees and min_n hyperparameter of the machine learning algorithm “ranger” and found that:
- compared to using the default values, our model using tuned hyperparameter values had better performance.
- the tuned model via Bayesian optimization method performs better than the Grid Search method
B) And using the {caret} package we applied the Grid Search method and the Adaptive Resampling Method to optimize mtry, splitrule , min.node.size and found that:
- compared to using the default values, our model using tuned hyperparameter values had better performance.
- the tuned model via Adaptive Resampling Method performs better than the Grid Search method.
- compared to using the relative new {tune} package, our model using the old {caret} package had better performance.
The results of our hyperparameter tuning experiments are displayed in the following table:
xyz <- tibble(Method = c("Default", "Grid Search", "Bayesian Optimization",
"Grid Search Caret", "Adaptive Resampling Method"),
AUC_value = c(auc_default$.estimate,
Finalize_grid[[1]]$.estimate,
Finalize_Bayesian[[1]]$.estimate,
auc_with_caret_gr$.estimate,
auc_with_caret$.estimate))
| Method | AUC_value |
|---|---|
| Default | 0.8235755 |
| Grid Search | 0.8248226 |
| Bayesian Optimization | 0.8295968 |
| Grid Search Caret | 0.8272427 |
| Adaptive Resampling Method | 0.8301066 |
Of course these results depend on the data set used and on the defined configuration(resampling, number of Iterations, cross validation, ..), you may come to a different conclusion if you use another data set with different configuration, but regardless of this dependency, our case study shows that the coding effort made for hyperparameter tuning using the tidymodels library is high and complex compared to the effort made by using the caret package. The caret package is more effective and leads to better performance.
I’m currently working on a new shiny application, which we can use for tuning hyperparameter of almost all the {parsnip} models using the {tune} package, and hopefully in this way we can reduce the complexity and the coding effort.
Thank you for your feedback also at kritiker2017@gmail.com