A well-done correlation analysis will lead us to a greater understanding of our data and empower us with valuable insights. A correlation analysis is a statistical technique that can show whether and how strongly pairs of variables are related, but all features must be numerical. Usually, we have numerous categorical variables in our data, that contains valuable information which might be hard to catch without a correlation analysis. So, is there an alternative or mathematical trick for us to use our data as it is and discover high correlation variables/values?
Correlations
Correlation works for quantifiable data in which numbers are meaningful, thus it cannot be calculated with categorical data such as gender, cities, or brands. These correlation coefficients might take values in the range of -1 to 1 (or -100% to 100%). It represents how closely the two variables are related: if this value is close to 0, it means that there is no relationship between the variables. When the value is positive, it means that as one variable gets larger the other gets larger. And, if they are negative it means that as one gets larger, the other gets smaller (often called an “inverse” correlation).
For the following examples, we will be using the lares library and dplyr’s Star Wars dataset. To install the former, run the following in your R session.
install.packages("lares")
Ranked Cross-Correlations
I am sure there must be another academic name for this specific kind of analysis, but as I haven’t found it out there yet, that is how I’ve been addressing it. Basically, it is the result of a sorted long-format correlation matrix from a dataset which may contain dates and other categorical features, that has been transformed with one-hot encoding and some additional features creations.
There are other authors who have done similar functions such as Alastair Rushworth with his inspectdf::inspect_cor() and Matt Dancho with correlationfunnel:: plot_correlation_funnel(). Both are great but are not exactly what I imagined and needed. So that’s why corr_cross() exists!
Ranked Cross-Correlations not only explains relationships of a specific target feature with the rest but the relationship of all values in your data in an easy to use and understand tabular format. It automatically converts categorical columns into numerical with one hot encoding (1s and 0s) and other smart groupings such as “others” labels for not very frequent values and new features out of date features.
OHSE (One Hot Smart Encoding) under the hood
One way to go around this issue is to study the correlation of a specific value in a categorical feature with the rest of numerical columns, but that wouldn’t be enough; we are losing too much information from other variables. Another solution could be to apply dummy variables or one-hot-encoding to every categorical value, but we will probably get thousands of columns and it may be a problem. Maybe, we could get the n most frequent values for each categorical feature and group the rest in a single column. We could also create new features out of date values such as weekdays, time of the day, minute of the day, week of the year. It would be great if we could also include the festivals from the country we are studying as well. And the currency exchange rate for each day? That’s what ohse() does. Note: Even though this functionality is used in the corr_cross function automatically, for better custom results I’d recommend to manually add it before the pipeline and use its parameters to get the features you’d want to check.
When is Ranked Cross-Correlations useful?
The most trivial use for Ranked Cross-Correlations is to understand a dataset further. Normally, the first thing you do when you encounter a dataset would be an EDA (Exploratory Data Analysis). You will understand now how many rows and columns there are, how many missing values per variable, how many numerical vs categorical features, their distributions, etc (check lares::plot_df()). The next logical step would be to check the interactions between variables and their values (correlations would work just fine but only if you have 100% numerical values).
Another useful case use is understanding clusters and what does each individual has in common for a group of observations. K-nearest neighbors algorithms might be great for creating similar groups but usually are hard to interpret, especially because they are unsupervised algorithms. Let’s say we ran K-means to group students and defined 5 groups. Now we need to understand, for each cluster, what do individuals have in common among themselves. Instead of exploring row by row, column by column, getting frequencies and making dozens of plots, why not run a ranked cross-correlation function to do the work for us?
Cross-correlate Star Wars dataset we must!
Let’s load dplyr’s starwars dataset and check how corr_cross() works with it. I would like to mention that I like Star Wars but am not a fan, so the insights mentioned bellow are 100% taken from the data and not from past knowledge.
library(lares)
library(dplyr)
data("starwars")
# Let's get rid of the lists inside the dataframe
df <- select(starwars, -starships, -vehicles, -films)
If you are not familiar with this dataset, I’ll quickly show its first six rows so you have an idea.
head(df)
name height mass hair_color skin_color eye_color birth_year gender homeworld species
1 Luke Skyw… 172 77 blond fair blue 19 male Tatooine Human
2 C-3PO 167 75 NA gold yellow 112 NA Tatooine Droid
3 R2-D2 96 32 NA white, bl… red 33 NA Naboo Droid
4 Darth Vad… 202 136 none white yellow 41.9 male Tatooine Human
5 Leia Orga… 150 49 brown light brown 19 female Alderaan Human
6 Owen Lars 178 120 brown, grey light blue 52 male Tatooine Human
Basically, we have all of the characters of the movies (87) with some specific characteristics such as height, mass, hair colour, etc. It’s a small (but fun) dataset! Let’s run what we came here to see:
corr_cross(df)
Which will plot you the following:
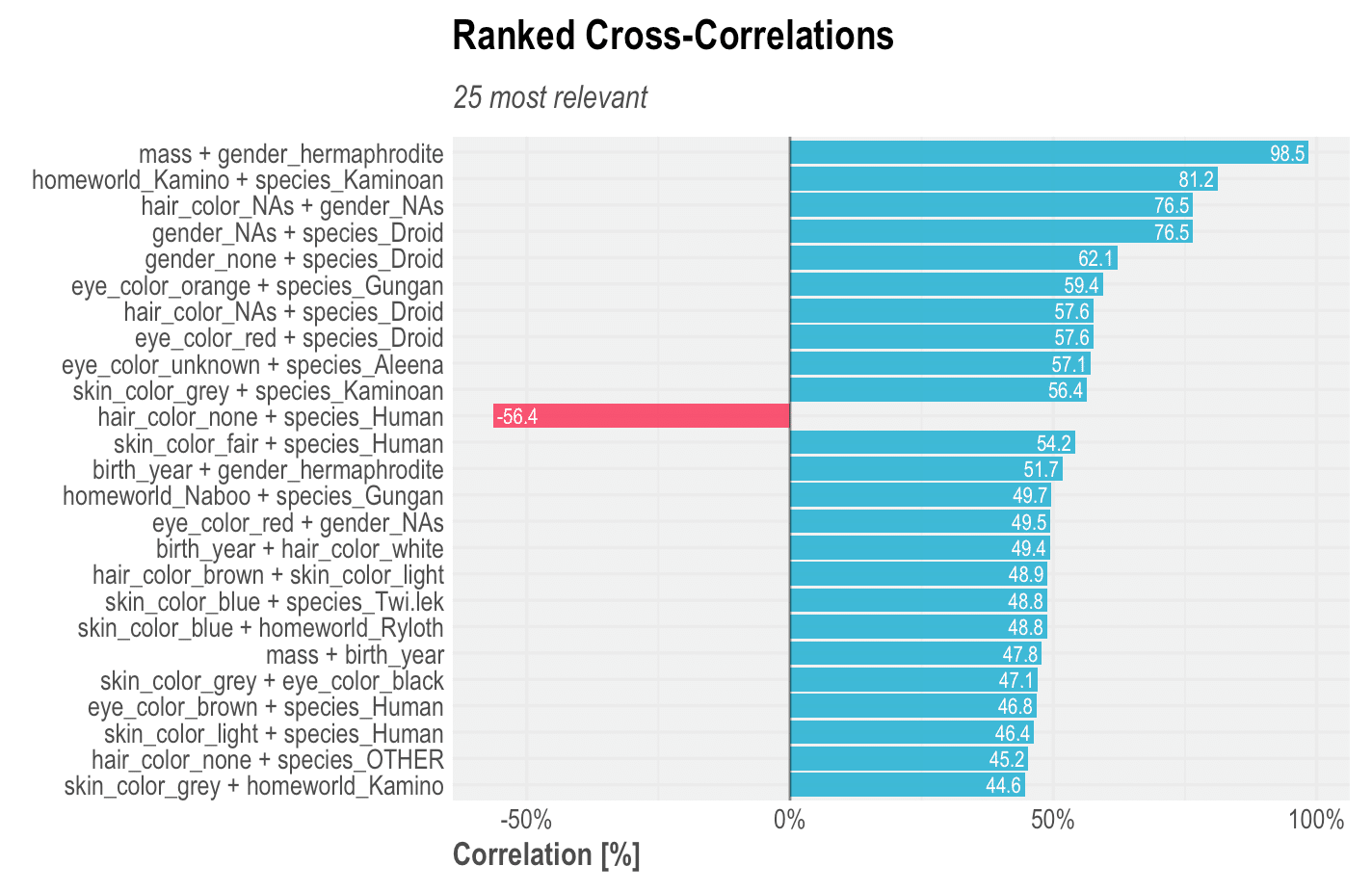
Yes, it is as easy as that. We can check the top correlations of variables and values ranked in descending order, excluding 100% correlations of course. From the plot above we can extract some interesting insights:
– Characters which are hermaphrodites are commonly fat as well! Jabba is the only hermaphrodite character and happens to be the fattest as well, followed by Grievous which mass consists only of 12% of Jabba’s. Also, it(?) is the second oldest character, leaving Yoda as the champion with 896 years old!
– Characters which are Kamionan (a species) usually come from Kamino, and have grey skin. The correlation might sound obvious because of both names, but if the planet was named Mars, then it would have been harder to detect. Interesting to notice that there is one human that also comes from Kamino (Boba Fett) and that is why the correlation is not 1 (100%).
– Droids commonly do not have gender (or not known), no hair colour, and red eyes.
– Gungans have orange eyes and their homeworld is Naboo.
– Most humans have hair colour defined (thus have hair) and fair skin colour. This is an inverse correlation example because when the character is human species the negative coefficient establishes that hair colour none is not common.

[The Illustrious Jabba The Hutt (…) | sideshow.com]
With these facts at hand, everyone would think I’m a Star Wars fan (rather than a data geek)! Leaving jokes aside, these insights are usually what we need to get from our datasets. With corr_cross() you find them as easily as that. Now, let’s check some other parameters to help us improve further our EDA.
Using the contains parameter you can check specific variables correlations. This option returns all Ranked Cross-Correlations that contains a certain string. Let’s say we want to check eye, hair, and skin colour in a single plot, then running corr_cross(df, contains = "color") will do. Give it a try!
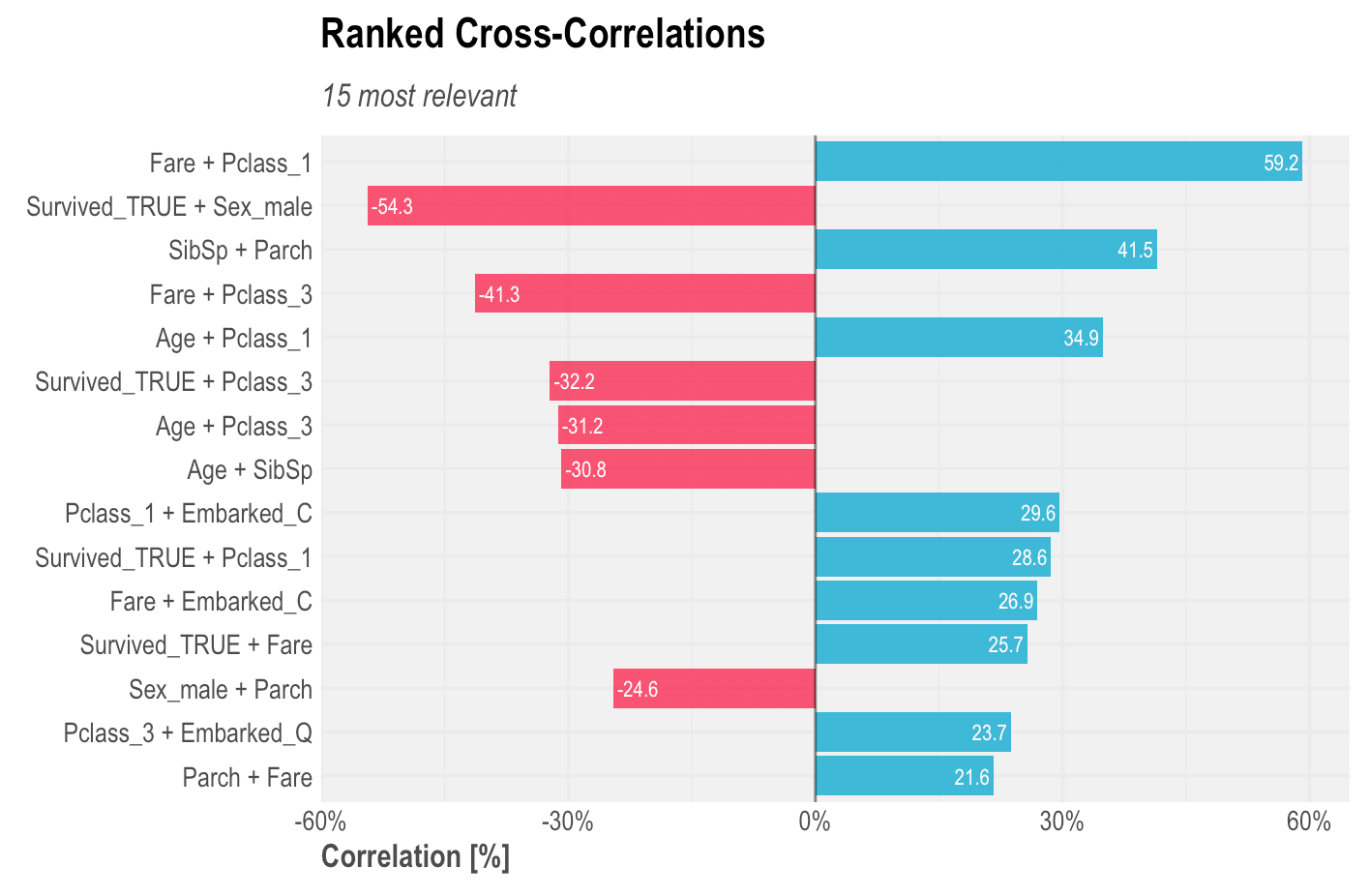
Also check the titanic data set’s Ranked Cross-Correlation; it doesn’t even need further explanations!
data(dft) # Let's get rid of some noisy columns first dft <- select(dft, -Cabin, -Ticket) corr_cross(dft, top = 15)
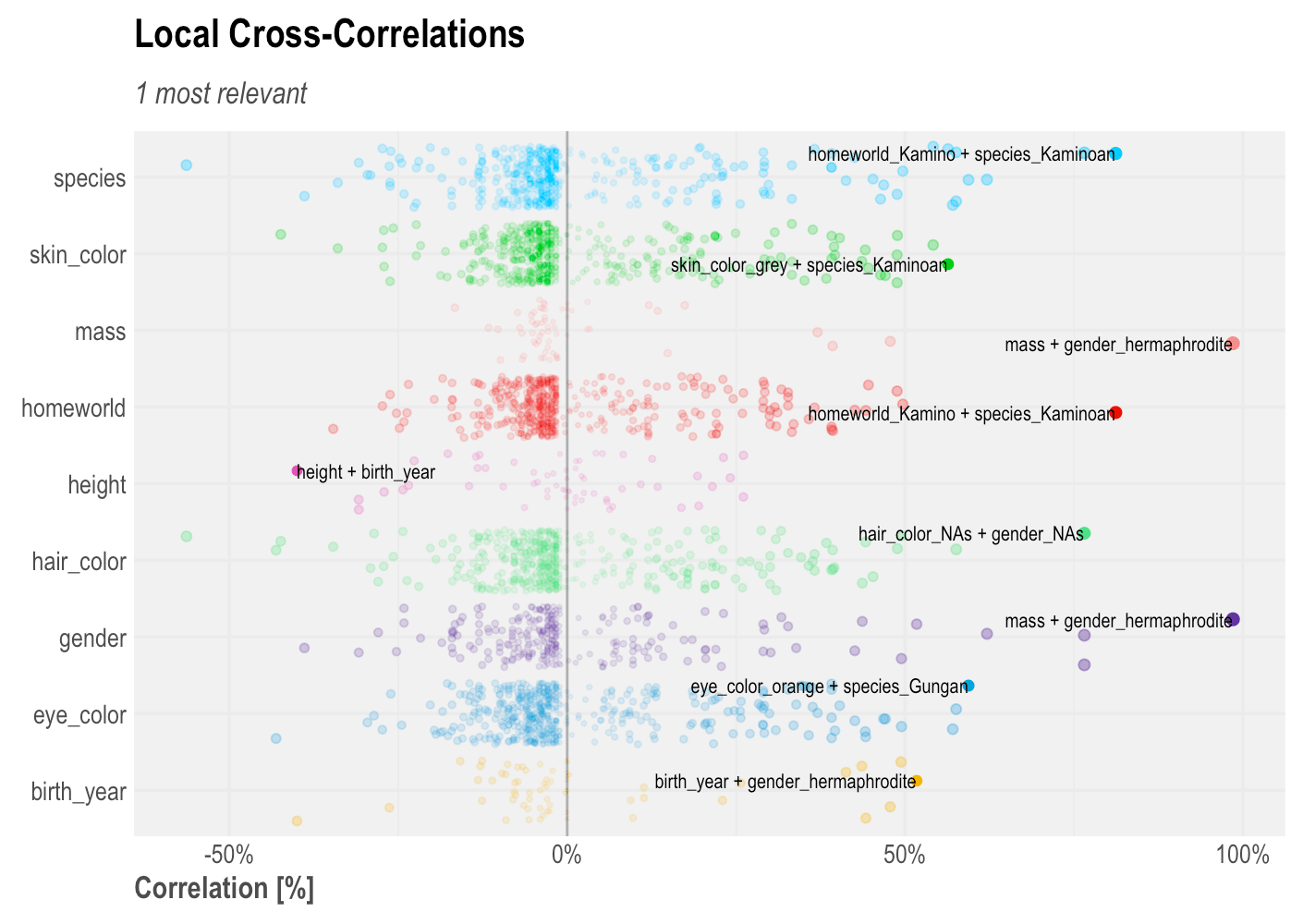
Local Cross-Correlation
There is another kind of cross-correlation that returns all correlations in a single plot, not necessarily ranked. This will help us understand the skewness or randomness of some correlations found. It will also highlight the highest correlations for each of the variables used.
corr_cross(df, type = 2)
or something like
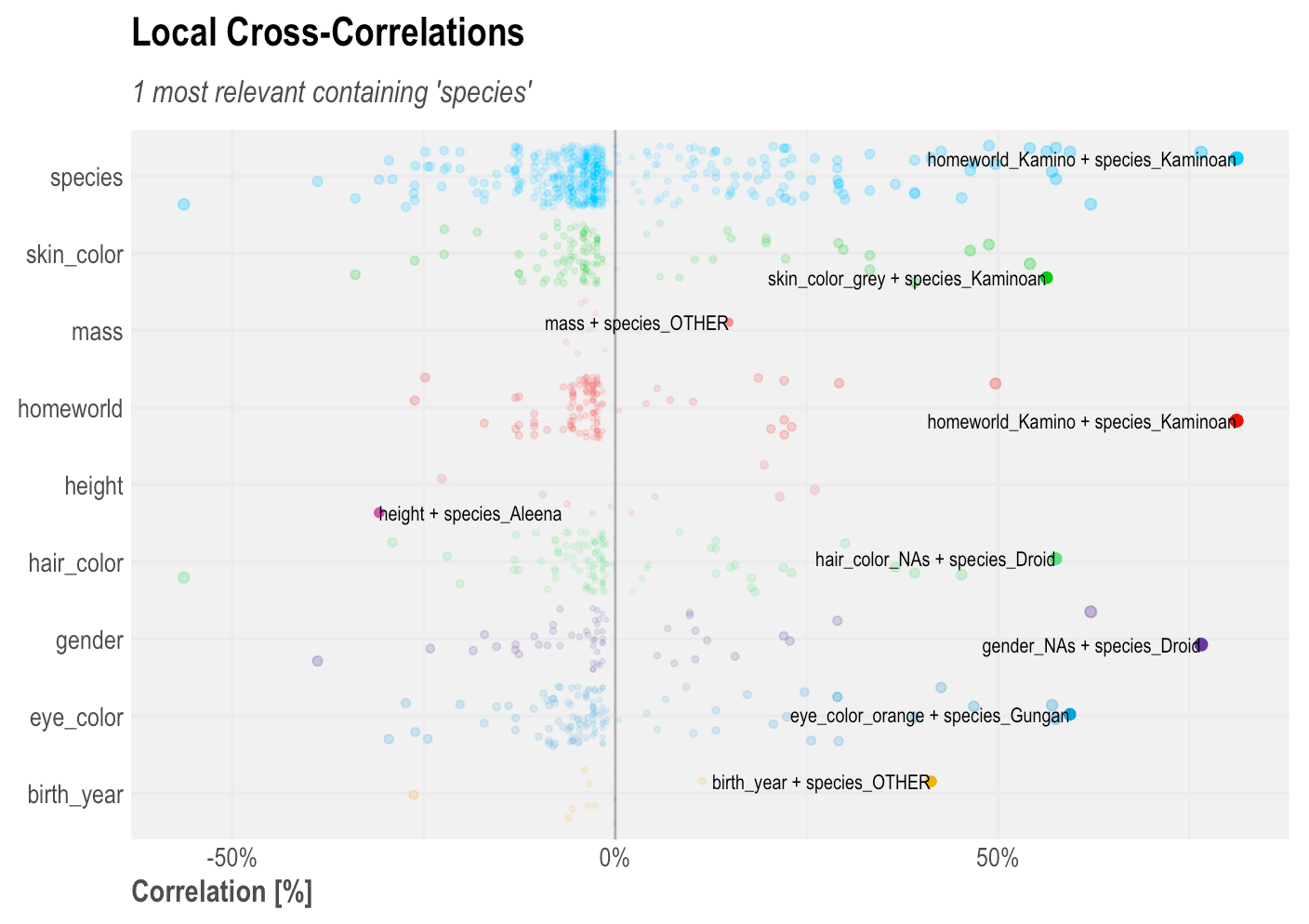
corr_cross(df, type = 2, contains = "species")
Other parameters
Additionally there are other parameters such as method for selecting which method you wish to use for calculating correlations (pearson, kendall, or spearman), plot for returning a data frame with the results instead of a plot, max for setting a ceiling different than 100%, top for showing more or less results for the Ranked Cross-Correlations, and some others which can be check in the documentation: ?cross_corr(). You might also fin useful its very close brothers: corr_var() and corr().
Feel free to share your results with other datasets and any interesting insights found with this method. I hope Ranked Cross-Correlations becomes an important tool for your future EDAs!