Pandas for reading an excel dataset. In this article, you are going to learn python about how to read the data source files if the downloaded or retrieved file is an excel sheet of a Microsoft product. We can read an excel file using the properties of pandas. It is necessary to import the pandas packages into your python script file. The below examples will help you in understanding how to read an excel file.
Consider the below simple excel sheet having the name “Data.xlsx” and “Data” as its sheet name and run the example codes to see different ways for reading an excel file. Note that you must provide the exact location path of a file located in your system drive or directory in the program code as shown in the below examples. Create a similar excel file with the name “Data.xlsx” and specify the sheet name as “Data” for your execution as shown in the below picture.
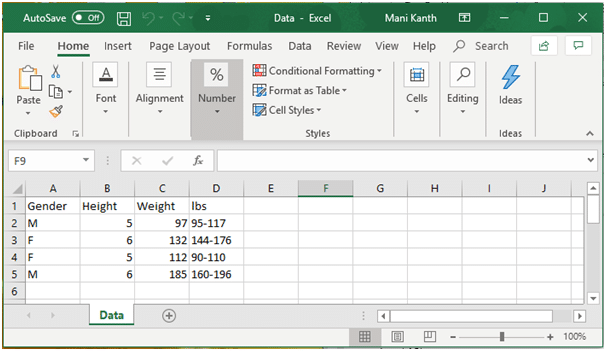
Import the pandas package for reading the excel files. Use “import pandas as pd” statement in your python script. We can use the method “pd.read_excel()” for reading an excel file by accessing the properties of the pandas library. Pass the file name and its path location with “.xlsx” file type as parameter for “pd.read_excel()” method.
Example 1
import pandas as pd
df=pd.read_excel("C:\\Users\\admin\\Desktop\\Data.xlsx")
print(df)
Gender Height Weight lbs
0 M 5 97 95-117
1 F 6 132 144-176
2 F 5 112 90-110
3 M 6 185 160-196
This example produces the above result after reading the data present in the excel file by assigning the index values for each row.
Example 2
import pandas as pd
df=pd.read_excel("C:\\Users\\admin\\Desktop\\Data.xlsx",sheet_name="Data")
print("Column headings:")
print(df.columns)
Column headings:
Index(['Gender', 'Height', 'Weight', 'lbs'], dtype='object')
In this example, we have used the parameter called “sheet_name”. The sheet name is the name of the sheet which exists after opening an excel file. This “read_excel()” method will read only the data which is present in that specific sheet name. In this case, the sheet name is “Data”. In this example, we are printing only the column names which are present in the excel sheet.
Now let us consider reading the specific column data available in an excel file. Run the below example code to see the result.
Example 3
import pandas as pd
df=pd.read_excel("C:\\Users\\admin\\Desktop\\Data.xlsx",sheet_name="Data")
gender = df['Gender']
height = df['Height']
weight = df['Weight']
lbs = df['lbs']
print("Column: Gender\n",gender)
print("Column: Height\n",height)
print("Column: Weight\n",weight)
print("Column: lbs\n",lbs)
Column: Gender
0 M
1 F
2 F
3 M
Name: Gender, dtype: object
Column: Height
0 5
1 6
2 5
3 6
Name: Height, dtype: int64
Column: Weight
0 97
1 132
2 112
3 185
Name: Weight, dtype: int64
Column: lbs
0 95-117
1 144-176
2 90-110
3 160-196
Name: lbs, dtype: object
In this example, we are reading the entire data of specific column names. We have implemented “df[‘Gender’]” to read all the rows in “Gender” column, “df[‘Height’]” to read all the rows in “Height” column, “df[‘Weight’]” to read all the rows in “Weight” column and “df[‘lbs’]” to read all the rows in “lbs” column name.
Consider the below example for reading the data in excel file by using the array index with iterations.
Example 4
import pandas as pd
df=pd.read_excel("C:\\Users\\admin\\Desktop\\Data.xlsx",sheet_name="Data")
print("Gender column:")
for i in df.index:
print(df['Gender'][I])
print("Weight column:")
for i in df.index:
print(df['Weight'][I])
print("Height column:")
for i in df.index:
print(df['Height'][I])
print("lbs column:")
for i in df.index:
print(df['lbs'][I])
Gender column:
M
F
F
M
Weight column:
97
132
112
185
Height column:
5
6
5
6
lbs column:
95-117
144-176
90-110
160-196
In the above example, we have implemented for loop for reading specific columns from an excel file. Each row is read by iterating the for loop followed by its column index locations.
The below example 5 explains about reading only a specific row of a particular column in an excel file. The row is read by specifying only the particular index location of the column name.
Example 5
import pandas as pd
df=pd.read_excel("C:\\Users\\admin\\Desktop\\Data.xlsx",sheet_name="Data")
gender = df['Gender']
print("Gender at index 3:",gender[3])
weight = df['Weight']
print("Weight at index 1:",weight[1])
height = df['Height']
print("Height at index 0:",height[0])
lbs = df['lbs']
print("lbs at index 2:",lbs[2])
Gender at index 3: M
Weight at index 1: 132
Height at index 0: 5
lbs at index 2: 90-110
From the above example, we can observe that “gender[3]” will display the string “M” for having the index location as 3. The “weight[1]” will display the number “132” for having the index location as 1, similarly, “height[0]” will display number “5” for having the index location as 0 and “lbs[2]” will display “90-110” for having index location as “2”.