Hey, my little friends! This is Santa! As you know Christmas is just around the corner. I’m receiving a lot of letters from you these days. But this year it will be different. I know that, sometimes, you ask me for a toy, but then you regret and say “Oh, I should have asked for something different!”. That’s why I will be using a recommender system to make suggestions, just in case you want something different from me!
Ok, let’s get started. I’m going to use this language called Python, let’s see if it works:
print('Hello North Pole!')
Hello North Pole!
It works!! HO – HO – HO!!!
Ok, let’s see the first letter from our little friends:
-
Dear Santa,
My name is Emma. This year I have been nice. It would make me happy to find a Melissa & Doug toy under the tree on Christmas morning!
Thank you.
Great! Let’s find out what Emma is asking for, then we can suggest something similar to her.
I’m going to import pandas library to load a dataset that contains previous toy ratings and comments from people.
That is going to be useful!
I will be using an extract of this file.
Since this is a tab-separated-values file, I need to use \t as a separator.
import pandas as pd
toys = pd.read_csv('amazon.tsv',sep='\t')
Ok, let’s take a look at the first lines:
toys.head()
I’m going to search for Melissa & Doug in the dataset.
toys[toys['product_title'] == 'Melissa & Doug']
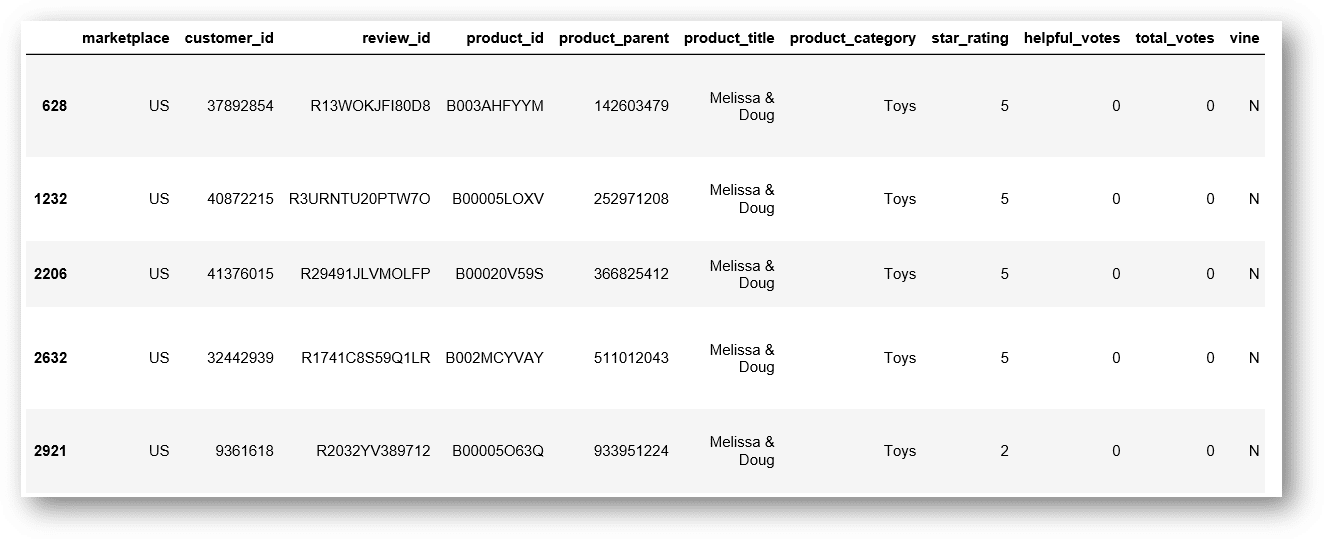
We create the dataset:
melissa_and_doug_df = toys[toys['product_title'] == 'Melissa & Doug'] melissa_and_doug_df.count()
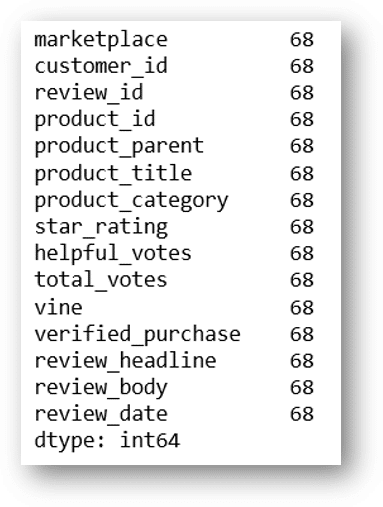
I can see 68 reviews of this product. I’m interested in the ratings provided by people. Let’s import seaborn library to see the graph.
We need to include %matplotlib inline if we are using Jupyter.
import seaborn as sns %matplotlib inline sns.countplot(x='star_rating',data=melissa_and_doug_df)
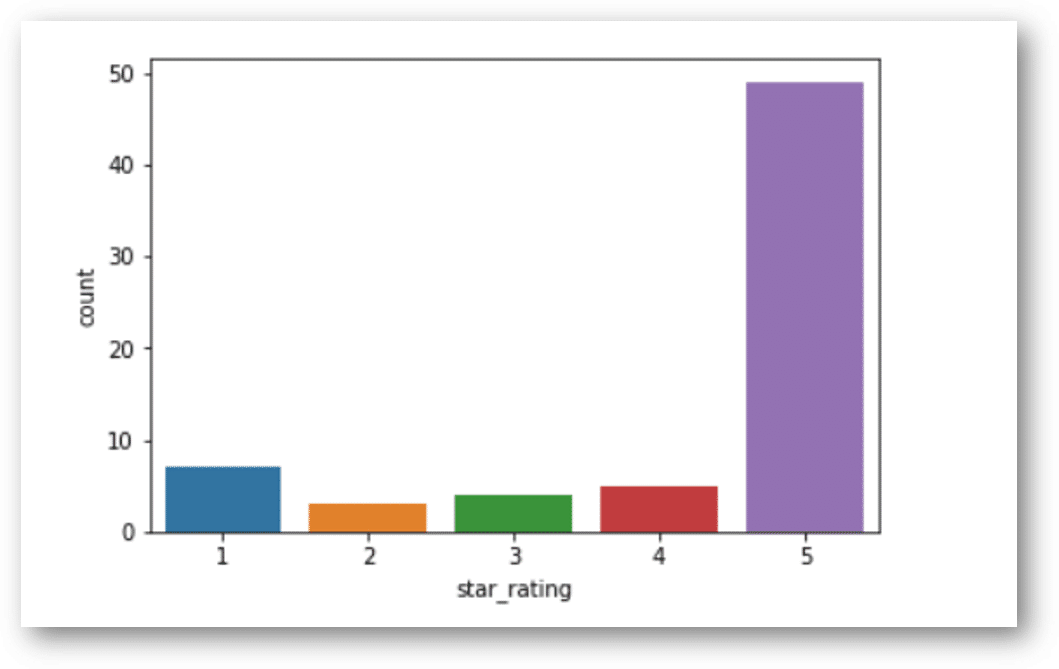
Most of the people rated 5 stars! That’s great, looks like a great present! No wonder Emma asked for it.
I want to know what people commented about this toy. I’m going to filter the best ratings and create a new dataset containing only the best rates:
melissa_and_doug_good_rating = melissa_and_doug_df[(melissa_and_doug_df['star_rating'] == 5) | (melissa_and_doug_df['star_rating'] == 4)]['review_body'] melissa_and_doug_good_rating

Hmmm I have lots of work these days, and I cannot read every comment, so I will create a Word Cloud to see the most relevant words!
from wordcloud import WordCloud, STOPWORDS
stopwords = set(STOPWORDS)
def melissa_dog_wordcloud(data):
wordcloud = WordCloud(
background_color='white',
stopwords = stopwords,
max_words = 200,
max_font_size = 40,
scale = 3,
random_state = 1
).generate(str(data))
fig = plt.figure(1, figsize=(20,20))
plt.axis('off')
plt.imshow(wordcloud)
plt.show()
I will invoke the melissa_doug_wordcloud function and I will pass in the dataset:
melissa_doug_wordcloud(melissa_and_doug_good_rating)
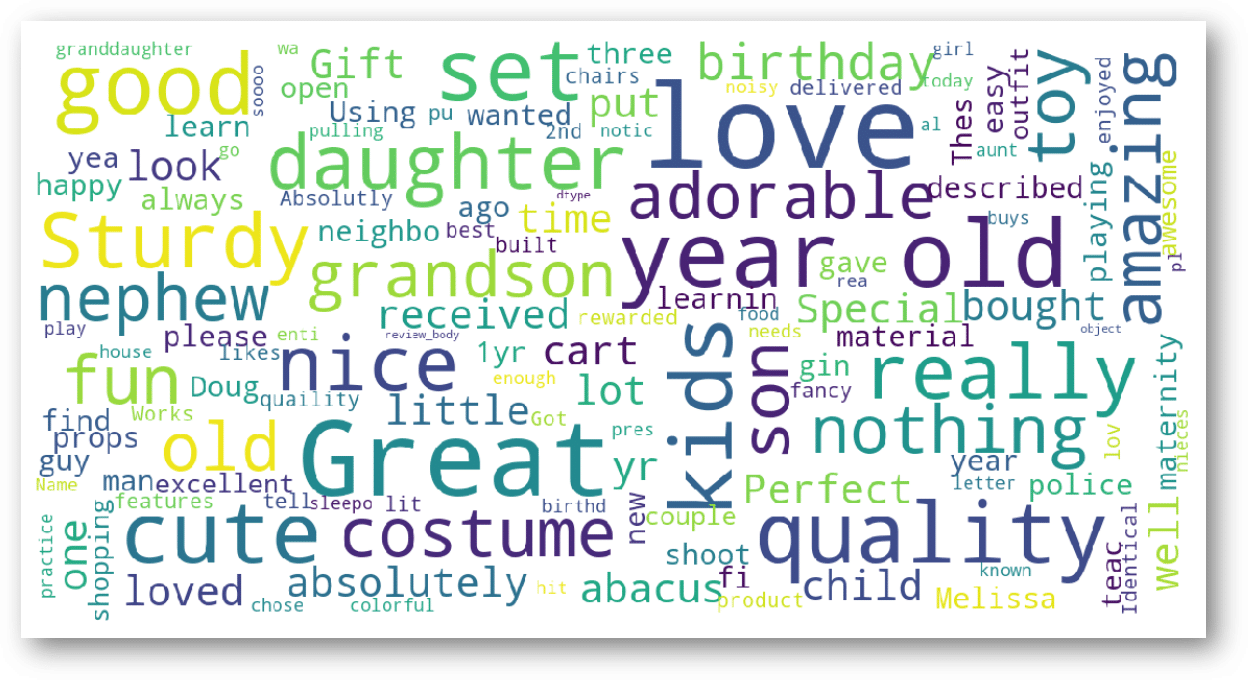
Wonderful!! I can see big words (words with most occurrences) like “Great”, “Love”, “Cute”, “Quality”.
Now, let’s see what we can suggest to Emma. Let’s create a pivot table. We will have customers is as index, and product title as column.
The values will be the ratings. This way we can see the values that people rated to every toy.
toysmat = toys.pivot_table(index='customer_id',columns='product_title',values='star_rating')
Let’s select only the values for Melissa & Doug:
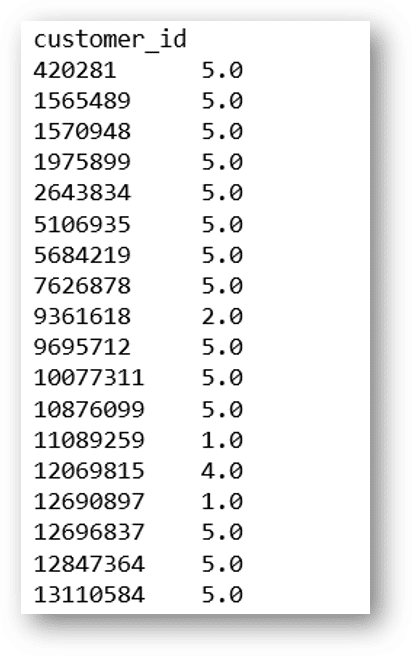
melissa_doug_ratings = toysmat['Melissa & Doug']
We remove null values, and see the result:
melissa_doug_ratings.dropna()
Ok, let’s call the corrwith method to see the correlation between data points. This way, we can see the most similar products:
similar_to_melissa_doug = toysmat.corrwith(melissa_doug_ratings) corr_melissa_doug = pd.DataFrame(similar_to_melissa_doug,columns=['Correlation']) corr_melissa_doug.dropna(inplace=True)
And then we have it!! We have a similar toy to suggest to Emma!

Let’s see the ratings for this toy:
melissa_and_doug_take_along_toolkit_df = toys[toys['product_title'] == 'Melissa & Doug Take-Along Tool Kit'] melissa_and_doug_take_along_toolkit_df
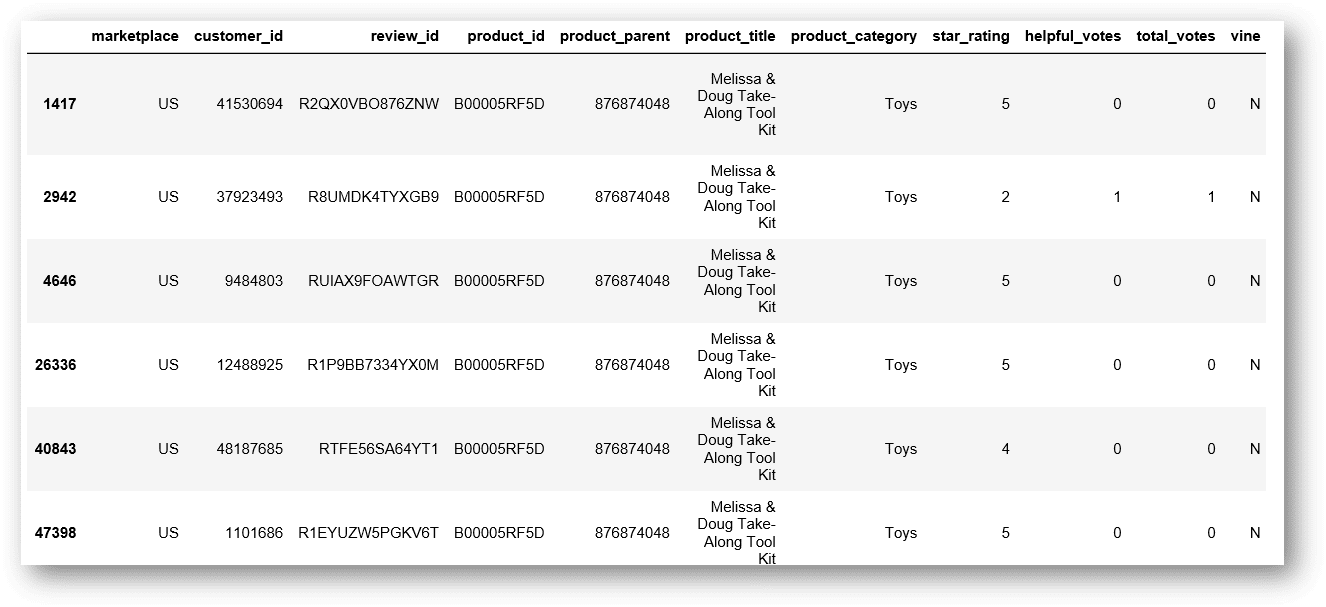
It has only one low rated comment. Let’s read it directly.
melissa_and_doug_take_along_toolkit_df['review_body'].iloc[1]
-
My daughter won’t touch this. She just doesn’t like it. And I can see why. It doesn’t make sense. There are a bunch of parts that don’t screw into anything or anywhere. It is just a bunch of pieces that look like they might be functional. I have no idea why this is rated so high. I would definitely not buy again.
Hmmmmmmmmm…OK! This person didn’t like it at all! Hmmm…hopefully this won’t be the case of our little friend Emma!
Let’s call Word Cloud to see the most common words of Melissa & Doug Take-Along Tool Kit.
melissa_and_doug_take_along_toolkit_rating = melissa_and_doug_take_along_toolkit_df[(melissa_and_doug_take_along_toolkit_df['star_rating'] == 5) | (melissa_and_doug_take_along_toolkit_df['star_rating'] == 4)]['review_body'] melissa_dog_wordcloud(melissa_and_doug_take_along_toolkit_rating)

Here we see words like “favorite”, “loves”, “good”. This will be definitely a great suggestion for Emma. I will reply to her later.
Ok, let’s see our next letter:
-
Dear Santa,
My name is Diego. This year I have been very nice…
HO – HO – HO!! You are not a kid anymore Diego!! HO – HO – HO!!!
Merry Christmas!!