Web Scraping is almost your go-to technique whenever you need data that are not readily available in your Data Warehouse or when it’s available online but not through an API which you can use to extract the information with HTML requests.
Let us say our objective is to find the popular Indian blogging platform. With that use-case in mind, Let us now see how can we find information for our analysis.
Data Source:
A quick google search for the keyword – indian bloggers lists this website as the first result. This website lists some of the most popular Indian bloggers and their blog links. Thus this website becomes our Data source from where we are going to scrape information for our further analysis.
Toolbox:
For this analysis, we are going to use Python programming language. The following are the list of packages that are required for this analysis.
- requests – For HTML request
- bs4 – The famous beautifulsoup for parsing html content and scrape required data
- re – For regular expressions and pattern matching
- matplotlib – For visualisation
Let us load the required libraries:
import requests from bs4 import BeautifulSoup, Comment import pandas as pd import re import matplotlib.pyplot as plt
HTTP Request
The first step in web scraping is just to make an HTTP request and get the URL content (remember this step is just to collect the content of the URL and it doesn’t scrape the required information).
url='https://indianbloggers.org/' content = requests.get(url).text
With that request using get(), a requests object with the url content is created and the .text method extracts the content of the object / URL.
Initialising Required Data objects:
For proceeding further in the analysis, we would require some data objects and here we are initializing those objects that would be used in subsequent steps.
#initalizing an empty dictionary that would be written as Pandas Dataframe and then CSV
d = {'title':[],'links':[]}
#initializing blog hosting category
cat = {'blogspot':0,'wordpress':0,'others':0}
As you can see, We’ve created two dictionaries – one for creatine a Pandas dataframe and then another one for the required blogging platforms that we would like to collect information about. So it’s basically Blogspot vs WordPress (and we’ve got others, that could include anything from custom domain to medium.com)
Begin Scraping
soup = BeautifulSoup(content, "html.parser")
for link in soup.find_all('a',):
if len(link.text.strip()) > 1 and bool(re.match('^http',link['href'])) and not bool(re.search('indianbloggers|twitter|facebook',link['href'])):
d['title'].append(link.text)
d['links'].append(link['href'])
#finding the blog hosting type
if re.search('blogspot',link['href']):
cat['blogspot']+=1
elif re.search('wordpress',link['href']):
cat['wordpress']+=1
else:
cat['others']+=1
#d['len'].append(len(link.text.strip()))
From the above code, you could notice that the scraping has been started with the function BeautifulSoup using the content that we extracted after our HTTP request. That’s just the starting of scraping. As we’ve defined in our objective, we are here to extract the links – especially domain names to analyze which blogging platform (which is defined by the URL’s domain name) is popular. With that in mind, we can be sure that we need to scrape anchor links (hyperlinks with the HTML tag `a`). During this process, we need to do some data cleaning steps. For example, there are some tags with nothing in it, which needs to bypassed and also we don’t need to get the hyperlinks of social media profile URLs present in the website. Hence, we manage to do data cleaning with a few regex expressions coupled with if conditions. Since we are extracting multiple URLs, we need to iterate our data extraction through a for loop to extract domain information and count the respective categories – blogpost, WordPress, others – and also build append to the dictionary that we created in the previous step which could be converted into a Pandas data frame.
Output Dataframe:
At the end of the previous step, we have got all the required information. For us to proceed further, we will convert the dictionary object `d` to a Pandas data frame which is a lot more flexible and useful in Data Analysis. The data frame then can be saved on your computer for future reference or any further analysis. Meanwhile, Let us also print some information about the Dataframe and data summary.
blog_list = pd.DataFrame(d).set_index('title')
print(blog_list.head())
blog_list.to_csv('blog_list.csv', encoding='utf-8')
print(str(len(blog_list.index))+' rows written')
print(cat)
>>>
links
title
Amit Agarwal http://www.labnol.org/
Jyotsna Kamat http://www.kamat.com/jyotsna/blog/
Amit Varma http://www.indiauncut.com/
Sidin Vadukut http://www.whatay.com/
Hawkeye http://hawkeyeview.blogspot.in/
363 rows written
{'wordpress': 49, 'blogspot': 106, 'others': 208}
As you can see in the result, the object `cat` gives us the required data to visualize.
Visualising the popular domain:
With the generated dictionary `cat`, let us now use matplotlib to visualize the data (with not much aesthetics).
#plotting the blog hosting type plt.bar(range(len(cat)), cat.values(), align='center') plt.xticks(range(len(cat)), cat.keys()) plt.show()
Gives this plot:
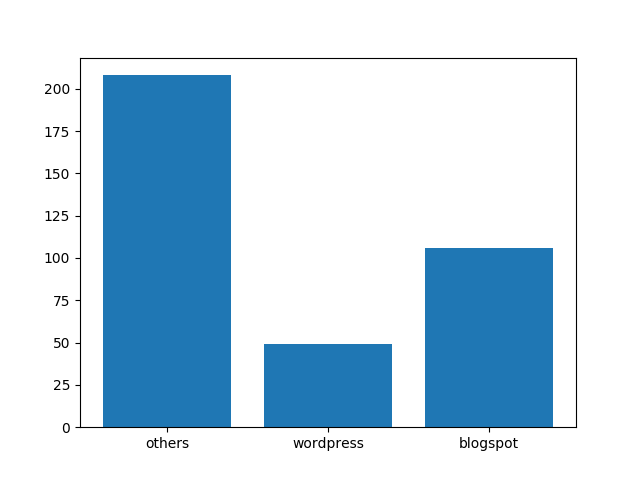
While the category ‘others’ (that includes custom domains and any other blogging platform) has won this race, between WordPress and Blogspot – blog post has turned out to be the winner – which also could be of the reason that the first movers were primarily on blog post platform and then they might have become popular and wound up on this site.
Final Notes:
Even though, This article was aimed with one purpose of finding the popular blogging platform. This article was aimed to help you get started with the basics of Web Scraping. If you are interested to know more regarding Web Scraping, You can check out this Datacamp tutorial. The complete code used here is available on my Github.